La requête gpt-4 api paraît simple. En pratique, elle cache la vraie question : comment brancher l’API OpenAI dans un projet web sans créer une usine à gaz lente, chère et impossible à maintenir ? Mon avis est assez net : l’appel API est la partie facile. Le dur, c’est tout ce qu’il y a autour, sécurité, coût, latence, données, cache et choix du modèle.
Réponse rapide : ce qu’il faut savoir avant d’utiliser GPT-4 API
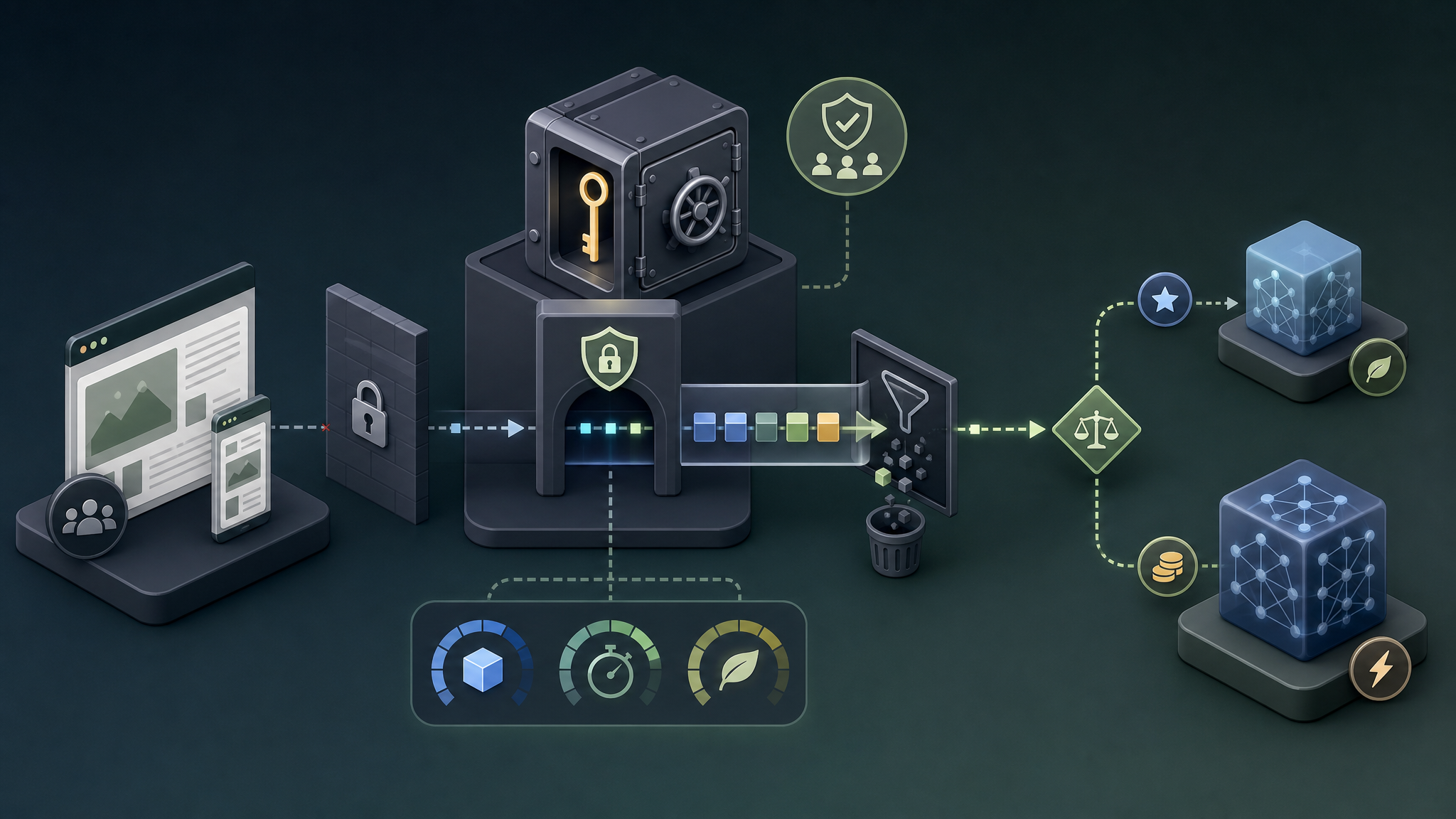
Avant de coder quoi que ce soit, verrouillez cinq points. Sinon vous allez vite payer pour des appels inutiles, ou pire, exposer une clé API dans le navigateur. Oui, ça arrive encore. Et franchement, c’est une faute de conception, pas une petite maladresse.
- L’accès passe par une clé API OpenAI créée depuis un compte avec facturation active.
- La clé doit rester côté serveur, jamais dans du JavaScript front-end.
- Le coût dépend des tokens envoyés et reçus, pas d’un forfait magique.
- Le modèle doit être choisi selon le niveau de qualité attendu, la latence et le volume.
- Une intégration propre prévoit timeout, cache, monitoring, fallback et revue des données.
En gros : ne partez pas de « comment appeler GPT-4 ? ». Partez de « quelle décision métier justifie un appel IA ici ? ». Ça change tout.
GPT-4 API, API OpenAI, GPT-4o : de quoi parle-t-on exactement ?
« GPT-4 API » est devenu un raccourci. Beaucoup de gens l’utilisent pour parler de l’API OpenAI en général, pas forcément du modèle GPT-4 historique. Or les modèles évoluent vite. GPT-4 classique a longtemps été la référence, mais il est désormais à traiter comme un modèle ancien et coûteux par rapport aux familles plus récentes, selon la documentation OpenAI.
Dans une intégration web moderne, vous manipulez surtout trois choses : une clé API, un endpoint et un nom de modèle. L’endpoint reçoit votre demande. Le modèle traite l’entrée. La clé prouve que votre serveur a le droit d’appeler l’API. Le reste, SDK, framework, queue, logs, vient seulement organiser ce flux.
La nuance compte. Si votre cahier des charges dit « utiliser GPT-4 », vous risquez de figer une décision technique qui n’est déjà plus optimale six mois plus tard. Je préfère écrire « utiliser l’API OpenAI avec un modèle adapté ». Moins sexy. Beaucoup plus maintenable.
OpenAI recommande aujourd’hui de passer par ses API et SDK récents pour les requêtes directes aux modèles. Vérifiez toujours la page officielle de tarification OpenAI avant de figer un budget, parce que les prix et les modèles bougent.
Dans quels cas intégrer une API GPT-4 dans un site ou un outil métier ?
Un LLM est utile quand la tâche demande de comprendre, reformuler, classer ou produire du texte à partir d’un contexte variable. Pas quand il faut afficher une donnée déjà connue. Ça paraît évident. Dans les projets, ça ne l’est pas toujours.
Les bons cas d’usage B2B ressemblent souvent à ça :
- préqualifier une demande support avant de l’envoyer à la bonne équipe ;
- résumer des tickets, comptes rendus ou documents internes ;
- classer des messages entrants avec une validation humaine ;
- aider un back-office à générer une première version de réponse ;
- enrichir une base de connaissances avec des tags ou des résumés courts ;
- assister une recherche sémantique, sans remplacer le moteur métier.
Les mauvais cas sont plus dangereux : génération de réponses critiques sans contrôle, appel IA sur chaque page vue, promesse de chatbot autonome qui « comprend tout », traitement de données sensibles sans gouvernance. Là, vous n’achetez pas de la productivité. Vous achetez une future réunion de crise.
Ma règle simple : si une règle métier classique résout le problème, commencez par elle. L’IA vient après, sur les zones floues.
Comment accéder à l’API : compte, clé, modèle et premier appel
Le chemin technique reste assez court. Créez un compte OpenAI, activez la facturation, générez une clé API, stockez-la dans une variable d’environnement côté serveur, puis appelez l’API depuis votre backend. Pas depuis le navigateur. Pas dans une app statique. Pas dans un script copié-collé dans une page WordPress.
Exemple minimal, volontairement court :
curl https://api.openai.com/v1/responses \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "modele-adapte-a-votre-usage",
"input": "Résume ce ticket support en 3 points actionnables."
}'Ce n’est pas le code qui fait la qualité de l’intégration. C’est ce que vous mettez autour : validation de l’entrée, taille maximale du prompt, gestion d’erreur, réponse par défaut si l’API ne répond pas, journalisation minimale, suivi des tokens.
Un détail souvent oublié : ne stockez pas tout le prompt en clair dans les logs. Pour déboguer, c’est confortable. Pour la confidentialité, c’est parfois désastreux. Conservez ce qui sert vraiment à piloter le service : identifiant de requête, modèle, nombre de tokens, latence, statut, coût estimé.
Choisir le bon modèle : qualité, coût, latence et contexte
Le meilleur modèle n’est pas toujours le plus puissant. Même si c’est tentant. Pour un site web ou un outil métier, je choisis rarement le modèle le plus cher par défaut. Je commence par le plus petit modèle capable de réussir le cas d’usage, puis je mesure.
| Option | Quand l’utiliser | Point de vigilance |
|---|---|---|
| GPT-4 classique | Besoin hérité, compatibilité avec une ancienne intégration, tests ponctuels | Souvent moins intéressant aujourd’hui en coût et évolution |
| GPT-4o ou modèle multimodal récent | Assistant plus qualitatif, analyse de contenu, usages texte et image selon disponibilité | À benchmarker sur vos vrais prompts, pas sur une démo |
| Modèle léger | Classification, résumé court, routage, extraction simple à gros volume | Peut rater les nuances métier, prévoir des tests |
| Pas d’IA | Règle fixe, calcul déterministe, affichage de données connues | C’est souvent l’option la plus sobre et la plus stable |
Le vrai arbitrage se fait sur quatre axes : qualité attendue, volume d’appels, temps de réponse acceptable, taille du contexte. Une aide interne utilisée par cinq personnes peut tolérer deux secondes de latence. Un module appelé à chaque interaction utilisateur, non. Là, le cache, l’asynchrone ou l’absence d’IA deviennent plus rationnels.
Petit test brutal : si vous ne savez pas expliquer pourquoi vous avez choisi ce modèle plutôt qu’un autre, vous n’avez pas encore choisi. Vous avez juste pris celui dont tout le monde parle.
Performance web : éviter que l’IA ralentisse l’expérience utilisateur
Un appel API externe ajoute de la latence. Même rapide, il reste dépendant d’un réseau, d’un fournisseur, d’un modèle et parfois d’une file d’attente. Le pire montage consiste à bloquer le rendu initial d’une page publique en attendant une réponse IA. Le résultat ? Une expérience molle, des erreurs aléatoires et une dépendance externe sur le chemin critique.
Pour préserver vos Core Web Vitals, gardez l’IA hors du rendu initial quand c’est possible. Lancez les traitements en arrière-plan. Pré-calculez les résultats en back-office. Servez une réponse en cache. Utilisez le streaming seulement si ça améliore réellement la perception utilisateur, pas parce que la démo est jolie.
- Définissez un timeout court et assumé.
- Prévoyez un fallback lisible si l’API ne répond pas.
- Cachez les réponses stables ou semi-stables.
- Traitez en batch les tâches internes non urgentes.
- Ne déclenchez pas un appel IA pour une information déjà calculée.
Bon, il y a une exception : certains assistants conversationnels doivent répondre en direct. Dans ce cas, il faut concevoir l’interface autour de cette attente. Message de chargement, réponse progressive, reprise possible. Ne faites pas semblant que 2,5 secondes n’existent pas.
Maintenance et sécurité : les erreurs à éviter en production
La sécurité d’une intégration gpt-4 api commence avec une phrase très simple : la clé API ne sort jamais du serveur. Jamais. Si elle est visible dans le navigateur, un utilisateur peut la récupérer, l’utiliser ailleurs et faire grimper votre facture. C’est une panne financière déguisée en bug front-end.
Point de sécurité
Ensuite viennent les sujets moins visibles, mais tout aussi sérieux. Validez les entrées pour éviter les prompts absurdes ou trop longs. Filtrez les sorties avant affichage si elles peuvent contenir des erreurs, du contenu sensible ou des instructions non souhaitées. Ajoutez une limite par utilisateur. Surveillez les pics de consommation. Testez les changements de modèle comme vous testeriez une dépendance applicative.
J’insiste sur ce point : un modèle n’est pas une fonction pure. Deux versions peuvent répondre différemment au même prompt. Si votre workflow métier dépend d’un format de sortie, demandez du JSON structuré, validez le schéma et prévoyez une erreur contrôlée. Sinon vous allez découvrir en production qu’une phrase aimable a remplacé un champ attendu. Très agaçant. Très évitable.
Côté données, appliquez une logique de minimisation. N’envoyez pas un dossier complet si trois champs suffisent. Masquez les données personnelles quand c’est possible. Documentez ce qui part vers le fournisseur, pourquoi, pendant combien de temps et avec quel niveau de contrôle humain. Pour un traitement sensible, faites relire le flux par la personne qui porte la conformité RGPD. Pas à la fin. Avant.
Sobriété numérique : réduire les appels, les tokens et les traitements inutiles
La sobriété numérique n’est pas une décoration verte collée sur un projet IA. Dans ce contexte, elle se traduit par des décisions très concrètes : moins d’appels, prompts plus courts, modèle proportionné, cache, batch, conservation minimale et mesure de l’usage réel.
Le bénéfice est triple. Moins de tokens, c’est moins de coût. Moins d’appels, c’est moins de latence. Moins de complexité, c’est moins de maintenance. Voilà pourquoi l’angle sobriété n’est pas moraliste ici. Il est juste rationnel.
Une bonne pratique consiste à écrire un budget de requête avant la mise en production. Par exemple : nombre d’appels maximum par utilisateur, taille maximale du prompt, taille maximale de réponse, durée de conservation des traces, seuil d’alerte mensuel. Rien de spectaculaire. Juste de la plomberie propre.
Et parfois, la meilleure optimisation consiste à supprimer l’appel. Un moteur de recherche interne, une règle de scoring, une FAQ bien structurée ou une page d’aide claire font mieux qu’un LLM pour une fraction du coût. C’est moins vendeur en réunion. C’est souvent plus solide.
Checklist avant mise en production d’une intégration GPT-4 API
Gardez cette liste courte. Si un point bloque, l’intégration n’est pas prête.
- Objectif métier formulé en une phrase, avec un indicateur de réussite.
- Modèle choisi à partir de tests réels, pas d’une intuition.
- Clé API stockée côté serveur, rotation prévue.
- Données envoyées revues, minimisées et documentées.
- Limites par utilisateur, par action ou par volume définies.
- Cache ou pré-calcul prévu pour les réponses réutilisables.
- Timeout, fallback et message d’erreur propres.
- Monitoring des tokens, coûts, latence et erreurs.
- Tests de régression sur prompts et formats de sortie.
- Documentation interne pour maintenir le flux dans six mois.
Si cette checklist semble lourde pour votre cas d’usage, c’est peut-être le signal que l’appel IA n’est pas justifié. Pas toujours, mais souvent.
FAQ rapide sur GPT-4 API
Est-ce que l’API GPT-4 est gratuite ?
Non, l’API OpenAI est généralement payante et facturée selon l’usage, notamment les tokens en entrée et en sortie. Les conditions peuvent changer, donc vérifiez la page officielle de tarification avant de lancer un budget.
Comment obtenir une clé API OpenAI ?
Il faut créer un compte OpenAI, activer la facturation si nécessaire, puis générer une clé depuis l’espace développeur. Cette clé doit être stockée côté serveur dans une variable d’environnement.
Quelle différence entre GPT-4, GPT-4 Turbo et GPT-4o ?
GPT-4 désigne le modèle historique, GPT-4 Turbo une génération optimisée apparue ensuite, et GPT-4o une famille plus récente orientée rapidité et multimodalité selon les disponibilités. Pour un nouveau projet, comparez les modèles actuels plutôt que de figer le nom GPT-4.
Peut-on appeler GPT-4 API directement depuis le navigateur ?
Non, pas proprement. Un appel direct depuis le navigateur expose la clé API. Utilisez un backend, même léger, pour protéger le secret, contrôler les droits et limiter les usages abusifs.
Comment réduire le coût d’une intégration GPT-4 API ?
Réduisez la taille des prompts, choisissez un modèle plus léger quand il suffit, mettez en cache les réponses stables, limitez les appels par utilisateur et surveillez les tokens. Le coût se pilote dès l’architecture, pas seulement après réception de la facture.
Quels risques RGPD avec une API d’IA ?
Le risque dépend des données envoyées, de la finalité, du fournisseur, de la conservation et du contrôle humain. Minimisez les données, évitez les informations sensibles si elles ne sont pas nécessaires et documentez le traitement avant la mise en production.
Quand une intégration IA mérite un audit technique
Une intégration IA mérite un audit dès qu’elle touche un parcours utilisateur, des données personnelles, un budget récurrent ou une décision métier. Pas besoin d’attendre que la facture explose ou que le chatbot raconte n’importe quoi.
L’audit doit regarder l’architecture, les flux de données, les coûts, la performance, les dépendances fournisseur, les prompts, les logs et le plan de maintenance. C’est exactement le terrain où une approche Architecture & Conseil Technique devient utile : décider quoi automatiser, quoi simplifier et quoi refuser.
La bonne intégration GPT-4 API n’est pas celle qui impressionne en démo. C’est celle qui reste compréhensible, mesurable et supportable six mois après sa mise en ligne. Moins de magie. Plus de maîtrise.
